이번 글에서는 Java에서 정규표현식을 사용하는 방법에 대해서 이야기하려고한다.
사실 정규표현식은 대부분의 여러 프로그래밍 언어에서 사용할 수 있도록 되어있다. 그래서 이름도 정규표현식이다.
사실 정규표현식은 대부분의 여러 프로그래밍 언어에서 사용할 수 있도록 되어있다.
그래서 이름도 정규표현식, Regular Expression인것이다.
이 글에선 Java에서의 사용에 대해 정리한다.
웹이든 앱이든 어플리케이션을 제작할 때 사용자 입력으로부터 유효성 검증을 받을 때 정규표현식을 사용한다.
["Java 정규표현식 사용법", "PHP 정규표현식 사용법"] 이런식으로 검색해서 찾으면, 아주 많은 다른사람들이 써놓은 글들이 나타난다.
그런데 사람사람마다 사용한 매소드, 함수들이 다르고 구현 방식들이 달라서 처음에 따라하기도 힘들고 헷갈렸었다.
그래서 그런 방식들을 정리해 놓고 Java에서 사용하는 것이 어떻게 다른지를 정리해 놓으려고 한다.
정규표현식을 다룰 수 있는 여러가지 Method들과 무엇을 할 수 있는지를 먼저 정리하고 어떤식으로 구현할 수 있는지 하나하나 정리한다.
| Method | 유효성 검사 가능 여부 | 문자열 재조합 가능 여부 | 기타 |
| String.match | 가능 | 불가능 | 일치 여부에 따라서 boolean값 반환 |
| String.replaceAll | 가능 | 가능 | 해당 표현식에 부합하는 부분을 치환(교체) |
| String.replaceFirst | 가능(replaceAll과 동일) | 제한적(replaceAll 하위호환) | 해당 표현식에 부합하는 부분을 치환(교체), 첫번째만 |
| String.split | 가능 | 가능 | 해당 표현식에 부합하는 부분을 기준으로 배열로 나눈다. |
| Pattern & Matcher | 가능 | 가능 | 다됨 |
1. String.match 방식
1.1. 유효성 검사
String.match(String regex) 메소드는 해당 문자열이 주어진 정규표현식에 부합하는지의 여부를 boolean(true, false)로 나타내준다. 정규표현식을 이용한 유효성 검사시에 가장 많이 사용되는 일반적인 방법이다.
String userId = "dumbalom009";
String password = "asdf!@#$";이렇게 정의되어 있다고 하고, 내가 만드는 어플리케이션의 userId, password조건은 아래와 같다고 하자.
| userId | 영문숫자만으로 8글자에서 20글자 |
| password | 영문숫자특수문자(?!@#$%) 8글자에서 20글자 |
match를 이용하여 아래와 같은 방식으로 검증할 수 있다.
String userId = "dumbalom009";
String password = "asdf!@#$";
String userIdRegex = "^[a-zA-Z0-9]{8,20}$";
String passwordRegex = "^[a-zA-Z0-9!@#$]{8,20}$";
boolean userIdResult = userId.matches(userIdRegex);
boolean passwordResult = password.matches(passwordRegex);
System.out.println(userIdResult ? "일치" : "불일치");
System.out.println(passwordResult ? "일치" : "불일치");
딱 일치되지 않는지를 검증한다.
2. String.replaceAll 방식
String.replaceAll(String regex) 매소드는 해당문자열중에 주어진 정규표현식에 부합하는 내용을 특정 내용으로 치환하는 매소드이다. 유효성 검사시에는 거의 사용되지 않으며, 규칙을 찾아서 내용을 보완할 때 주로 많이 사용된다.
2.1 유효성 검사
String userId = "dumbalom009";
String password = "asdf!@#$";이렇게 정의되어 있다고 하고, 내가 만드는 어플리케이션의 userId, password조건은 아래와 같다고 하자.
| userId | 영문숫자만으로 8글자에서 20글자 |
| password | 영문숫자특수문자(?!@#$%) 8글자에서 20글자 |
replaceAll을 이용하여 아래와 같은 방식으로 검증할 수 있다.
String userId = "dumbalom009";
String password = "asdf!@#$";
String userIdRegex = "^[a-zA-Z0-9]{8,20}$";
String passwordRegex = "^[a-zA-Z0-9!@#$]{8,20}$";
boolean userIdResult = userId.replaceAll(userIdRegex, "").equals("");
boolean passwordResult = password.replaceAll(passwordRegex, "").equals("");
System.out.println(userIdResult ? "일치" : "불일치");
System.out.println(passwordResult ? "일치" : "불일치");String.match 방식은 해당 정규식에 부합하는지를 바로 검증해 줬다면,
String.replaceAll 방식은 정규식에 부합하는 내용을 특정문자로 치환한다는 특성을 이용하여 공백으로 치환하고 공백과 비교한다.
그러나, 이 예제에서는 공백으로 비교했기 때문에 처음부터 입력 문자열이 공백이었다면 이 코드에서는 부합한다고 통과될 것이다. 그렇기 때문에 이렇게 가능하다 정도로만 알고 실제로 사용하지 않는것이 좋다.
2.2 문자열 가공 (재조합)
예를들어 아래와 같은 문자열 데이터가 주어졌고, 여기에서 데이터를 뽑아내야 한다.
사과가 10개 있다.
배는 14개가 있다.
바나나는 12341234개가 있다.
이런 데이터에서 값을 뽑아낼 때 정규식의 그룹기능을 이용할 수 있다.
String str = "사과가 10개 있다.\r\n"
+ "배는 14개가 있다.\r\n"
+ "바나나는 12341234개가 있다.";
String regex = "([가-힣]+)[은는이가] ([0-9]+)개.*있다.";
String result = str.replaceAll(regex, "$1, $2");
System.out.println(result);결과는

위와 같다.
정규식으로 치환할 때 정규식에서 소괄호"()"로 묶으면 하나의 그룹이 되는데, 이 그룹을 표현할 때 소괄호"()"로 묶은 순서대로 $1, $2, $3, ....., $n과 같이 표현한다.
이것을 응용하여 위의 코드를 아래와 같이 변경하면
String str = "사과가 10개 있다.\r\n"
+ "배는 14개가 있다.\r\n"
+ "바나나는 12341234개가 있다.";
String regex = "([가-힣]+)[은는이가] ([0-9]+)개.*있다.";
String result = str.replaceAll(regex, "{\"item\": \"$1\", \"quantity\": \"$2\"}");
System.out.println(result);
이렇게 Json으로도 응용할 수 있다.
위의 문자열을 보면 일정한 패턴이 있는데,

파란색으로 칠해져있는 부분은 고정이고 검은색으로 칠해져 있는 부분은 유동적이다.
고정적인 부분은 그대로 이용해주고, 유동적인 부분의 패턴을 포용할 수 있는 정규식으로 대체하고 그룹화한다음 replaceAll할 때 $n으로 표현해주면 원하는 포멧에 맛게 문자열을 가공할 수 있다.
3. String.replaceFirst 방식
3.1. 유효성 검사
String.replaceFirst의 유효성 검사 방식은 String.replaceAll의 유효성 검사 방식과 동일하다.
왜냐하면 어차피 가공하고 확인해야할 데이터가 한개이기 때문이다. 비밀번호가 한 문자열로 두개가 들어오지는 않기 때문에, 동일한 방식으로 검증이 가능하므로 따로 설명하지 않는다.
3.2. 문자열 가공 (재조합)
위의 표에 나와있듯이 매우 제한적으로 가능하다. 왜냐하면 매소드의 이름에서도 알 수 있듯이 첫번째 것만 처리되기 때문에 여러 문장에 여러 데이터가 있는 위와같은 경우에는 사용할 수 없고, 한 문장에 있는 데이터를 뽑아낼 때 사용할 수 있다.
바로 코드를 보자.
String str = "사과가 10개 있다.\r\n"
+ "배는 14개가 있다.\r\n"
+ "바나나는 12341234개가 있다.";
String regex = "([가-힣]+)[은는이가] ([0-9]+)개.*있다.";
String result = str.replaceFirst(regex, "$1, $2");
System.out.println(result);이 코드는 2.2의 예제의 코드에서 replaceAll을 replaceFirst로만 고친 코드이다.
결과는 아래와 같다.

예상했듯이 첫번째 것만 처리가 되었고, 두번째 세번째 문장은 처리되지 않았다.
그렇기 때문에 아래와 같이 한 문장안에 뽑아내야할 데이터가 있을 때와 같은 제한적인 상황에서만 사용될 수 있다.
String str = "둠발롬이 성남에서 구로로 출근합니다.";
String regex = "([가-힣]+)[은는이가] ([가-힣]+)에서 ([가-힣]+)로 ([가-힣]+)합니다.";
String result = str.replaceFirst(regex, "$1, $2, $3, $4");
System.out.println(result);결과는 아래와 같다.

그런데 이런 상황에서는 replaceAll을 사용해도 결과가 동일하기 때문에 그냥 replaceAll만 사용해도 된다.
4. String.split 방식
String.split은 해당 규칙을 구분자로 하여 배열을 만들어주는 매소드이다.
String str = "둠발롬이 궁으로 팟지를 먹었다.";
String regex = " ";
String[] result = str.split(regex);
System.out.println(Arrays.asList(result));이 코드를 실행하면 아래와 같은 결과가 나온다.

4.1. 유효성 검사
사실 이것도 replaceAll을 이용한 꼼수에 가까운 방법이기 때문에, 실제 사용할 때 추천하지 않는다. 다만 이런 방법도 있으며 이런식으로도 응용할 수 있다는 것만 알아두자.
결국 배열로 쪼갤 때 구분자로 정규식을 이용하기 때문에, 사용자가 정규식에 딱 맞는 값을 입력했다면, 해당 정규식을 이용해서 split했을 때 result배열의 length가 0이여야 한다.
그렇기 때문에 result배열의 length가 0일 때 사용자가 올바른 값을 입력했다고 판단해도 된다는 방식이다.
아래는 각각 코드와 결과이다.
String userId = "dumbal!om009";
String password = "asdf!@#$";
String userIdRegex = "^[a-zA-Z0-9]{8,20}$";
String passwordRegex = "^[a-zA-Z0-9!@#$]{8,20}$";
boolean userIdResult = userId.split(userIdRegex).length == 0;
boolean passwordResult = password.split(passwordRegex).length == 0;
System.out.println(userIdResult ? "일치" : "불일치");
System.out.println(passwordResult ? "일치" : "불일치");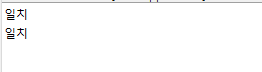
4.2. 문자열 재조합 (가공)
사실 split을 이용하여 replaceAll의 기본기능처럼 사용할 수 있다. 변경할 문자로 자르고 새로운 문자로 String.join 메소드를 이용해서 다시 붙이면 된다. 그렇지만 이미 replaceAll이라는 좋은 메소드가 있고 split을 하면서 새로 생길 문자열들과 그로 인해서 소비될 자원들을 생각하면 사용하지 않는것이 좋다.
split으로 "a"를 잘라서 "b"로 붙이면 치환,
split으로 "a"를 잘라서 ""으로 붙이면 제거가 된다.
위의 표를 작성하면서도 가능하긴 한데 가능하다고 적는게 좋을지 고민하긴 했지만, 가능은 하므로 가능하다고 적었다.
하지만 데이터를 주고받는데, ","를 구분으로 여러 데이터를 한꺼번에 넘기는 상황에서는 사용하면 편리하므로 알고만 있자.
'푸로그래밍 > JAVA' 카테고리의 다른 글
| [JAVA, Kotlin] OkHttp3 인증서 신뢰 (1) | 2024.03.08 |
|---|---|
| [JAVA] File MD5 checksum (0) | 2023.12.21 |
| [JAVA] 정규표현식 사용 방법 - 2 (Pattern, Matcher) (0) | 2021.03.26 |
